[R] 데이터 처리의 새로운 강자, dplyr 패키지
2014-02-25
dplyr
R
데이터 분석에서 가장 많은 시간을 차지하는 것은 데이터를 분석에 필요한 형태로 만드는 데이터 전처리 과정입니다. 우리가 공부하면서 보게 되는 책에 있는 예제는 말 그대로 예제일 뿐이지 실제 데이터 분석 업무에서는 바로 모델링이나 시각화에 적합한 형태의 데이터를 얻기 위해서는 지루하고 복잡한 과정을 거치게 됩니다. 데이터 분석 프로젝트에 걸리는 시간의 절반 이상은 데이터의 전처리, 변환, 필터링이 차지하게 되는 것이 보통입니다.
R 언어 자체에도 데이터 전처리를 위한 많은 함수가 포함되어 있습니다. 여기에 각종 패키지의 도움을 받는다면 더욱 쉽고 빠르게 전처리 과정을 마칠 수가 있습니다. 이번 포스팅에서는 최근 dplyr이라는 패키지가 새로 발표되어 인터넷상에서 좋은 평가를 받고 있기에 패키지 안에 포함된 예제를 이용하여 기본 사용법을 정리해 보도록 하겠습니다.
dplyr 패키지?
dplyr 패키지는 Hadley Wickham가 작성한 데이터 처리에 특화된 R 패키지입니다. 이 분이 지금까지 작성한 유명한 R 패키지로는 ggplot2, plyr, reshape2등이 있으며 이미 많은 분들이 사용하고 있으리라 생각합니다.
데이터 처리에 특화된 유용한 패키지로는 역시 Hadley Wickham이 만든 plyr이라는 패키지가 있었습니다. 그러나 plyr은 편리하긴 했지만 모든 함수가 R로 작성되어서 처리 속도가 느리다는 단점이 있었습니다. 이에 반해 dplyr은 C++로 작성되어 불필요한 함수를 불러오지 않기 때문에 매우 빠른 처리 속도를 자랑합니다.
dplyr 패키지는 데이터 프레임을 처리하는 함수군으로 구성되어 있습니다. 하지만 그 밖에도 다음 형식의 데이터를 이용할 수 있습니다.
- data.table : data.table 패키지와 사용
- 각종 데이터베이스 : 현재 MySQL, PostgreSQL, SQLite, BigQuery를 지원
- 데이터 큐브 : dplyr 패키지 내부에 실험적으로 내장됨
dplyr 패키지 사용법
먼저 포스팅에서 소개할 dplyr 패키지와 데이터 셋 hflight를 설치하고 함수 library()를 이용해 함수군 및 데이터를 불러옵니다.
> install.packages(c("dplyr", "hflights"))> library(dplyr)
> library(hflights)dplyr 패키지의 기본이 되는 것은 다음 5개 함수입니다.
| 함수명 | 내용 | 유사함수 |
|---|---|---|
| filter() | 지정한 조건식에 맞는 데이터 추출 | subset() |
| select() | 열의 추출 | data[, c(“Year”, “Month”)] |
| mutate() | 열 추가 | transform() |
| arrange() | 정렬 | order(), sort() |
| summarise() | 집계 | aggregate() |
여기에 group_by() 함수를 추가로 이용하면 그룹별로 다양한 집계를 할 수 있습니다.
예제에 사용된 데이터는 미국 휴스턴에서 출발하는 모든 비행기의 2011년 이착륙기록이 수록된 것으로 227,496건의 이착륙기록에 대해 21개 항목을 수집한 데이터입니다.
> dim(hflights)#> [1] 227496 21hflights 데이터는 관측치의 수가 많기 때문에 tbl_df 형식으로 변환해서 사용하는 것을 추천합니다.
> hflights_df <- tbl_df(hflights)
> hflights_df#> # A tibble: 227,496 x 21
#> Year Month DayofMonth DayOfWeek DepTime ArrTime UniqueCarrier
#> * <int> <int> <int> <int> <int> <int> <chr>
#> 1 2011 1 1 6 1400 1500 AA
#> 2 2011 1 2 7 1401 1501 AA
#> 3 2011 1 3 1 1352 1502 AA
#> 4 2011 1 4 2 1403 1513 AA
#> 5 2011 1 5 3 1405 1507 AA
#> 6 2011 1 6 4 1359 1503 AA
#> 7 2011 1 7 5 1359 1509 AA
#> 8 2011 1 8 6 1355 1454 AA
#> 9 2011 1 9 7 1443 1554 AA
#> 10 2011 1 10 1 1443 1553 AA
#> # ... with 227,486 more rows, and 14 more variables: FlightNum <int>,
#> # TailNum <chr>, ActualElapsedTime <int>, AirTime <int>, ArrDelay <int>,
#> # DepDelay <int>, Origin <chr>, Dest <chr>, Distance <int>,
#> # TaxiIn <int>, TaxiOut <int>, Cancelled <int>, CancellationCode <chr>,
#> # Diverted <int>이렇게 하면 모든 데이터를 화면에 출력하는 실수를 방지할 수 있습니다.
함수 filter()를 이용한 데이터 추출
함수 filter()는 조건에 따라 행(row)을 추출합니다. 사용방법은 첫 번째 인수로 추출 대상이 되는 데이터 프레임을 지정하고, 두 번째 인수로 추출하고 싶은 행의 조건을 지정합니다. 이 서술방법은 dplyr 패키지의 다른 기본함수에도 똑같이 적용됩니다. AND 조건문 콤마(,)로 구별하거나 & 연산자를 사용해도 되며 OR 조건문은 | 연산자를 이용합니다.
> # 1월 1일 데이터 추출
> filter(hflights_df, Month == 1, DayofMonth == 1)#> # A tibble: 552 x 21
#> Year Month DayofMonth DayOfWeek DepTime ArrTime UniqueCarrier
#> <int> <int> <int> <int> <int> <int> <chr>
#> 1 2011 1 1 6 1400 1500 AA
#> 2 2011 1 1 6 728 840 AA
#> 3 2011 1 1 6 1631 1736 AA
#> 4 2011 1 1 6 1756 2112 AA
#> 5 2011 1 1 6 1012 1347 AA
#> 6 2011 1 1 6 1211 1325 AA
#> 7 2011 1 1 6 557 906 AA
#> 8 2011 1 1 6 1824 2106 AS
#> 9 2011 1 1 6 654 1124 B6
#> 10 2011 1 1 6 1639 2110 B6
#> # ... with 542 more rows, and 14 more variables: FlightNum <int>,
#> # TailNum <chr>, ActualElapsedTime <int>, AirTime <int>, ArrDelay <int>,
#> # DepDelay <int>, Origin <chr>, Dest <chr>, Distance <int>,
#> # TaxiIn <int>, TaxiOut <int>, Cancelled <int>, CancellationCode <chr>,
#> # Diverted <int>> # 1월 혹은 2월 데이터 추출
> filter(hflights_df, Month == 1 | Month == 2)#> # A tibble: 36,038 x 21
#> Year Month DayofMonth DayOfWeek DepTime ArrTime UniqueCarrier
#> <int> <int> <int> <int> <int> <int> <chr>
#> 1 2011 1 1 6 1400 1500 AA
#> 2 2011 1 2 7 1401 1501 AA
#> 3 2011 1 3 1 1352 1502 AA
#> 4 2011 1 4 2 1403 1513 AA
#> 5 2011 1 5 3 1405 1507 AA
#> 6 2011 1 6 4 1359 1503 AA
#> 7 2011 1 7 5 1359 1509 AA
#> 8 2011 1 8 6 1355 1454 AA
#> 9 2011 1 9 7 1443 1554 AA
#> 10 2011 1 10 1 1443 1553 AA
#> # ... with 36,028 more rows, and 14 more variables: FlightNum <int>,
#> # TailNum <chr>, ActualElapsedTime <int>, AirTime <int>, ArrDelay <int>,
#> # DepDelay <int>, Origin <chr>, Dest <chr>, Distance <int>,
#> # TaxiIn <int>, TaxiOut <int>, Cancelled <int>, CancellationCode <chr>,
#> # Diverted <int>함수 arrange()를 이용한 정렬
함수 arrange()는 지정한 열을 기준으로 작은 값으로부터 큰 값의 순으로 데이터를 정렬합니다. 역순으로 정렬할 때는 함수 desc()를 함께 사용합니다.
> # 데이터를 ArrDelay, Month, Year 순으로 정렬
> arrange(hflights_df, ArrDelay, Month, Year)#> # A tibble: 227,496 x 21
#> Year Month DayofMonth DayOfWeek DepTime ArrTime UniqueCarrier
#> <int> <int> <int> <int> <int> <int> <chr>
#> 1 2011 7 3 7 1914 2039 XE
#> 2 2011 12 25 7 741 926 OO
#> 3 2011 8 21 7 935 1039 OO
#> 4 2011 8 31 3 934 1039 OO
#> 5 2011 8 26 5 2107 2205 OO
#> 6 2011 12 24 6 2129 2337 CO
#> 7 2011 8 28 7 2059 2206 OO
#> 8 2011 8 29 1 935 1041 OO
#> 9 2011 8 18 4 939 1043 OO
#> 10 2011 12 24 6 2117 2258 CO
#> # ... with 227,486 more rows, and 14 more variables: FlightNum <int>,
#> # TailNum <chr>, ActualElapsedTime <int>, AirTime <int>, ArrDelay <int>,
#> # DepDelay <int>, Origin <chr>, Dest <chr>, Distance <int>,
#> # TaxiIn <int>, TaxiOut <int>, Cancelled <int>, CancellationCode <chr>,
#> # Diverted <int>> # 데이터를 Month의 큰 값으로 부터 작은 값 순으로 정렬
> arrange(hflights_df, desc(Month))#> # A tibble: 227,496 x 21
#> Year Month DayofMonth DayOfWeek DepTime ArrTime UniqueCarrier
#> <int> <int> <int> <int> <int> <int> <chr>
#> 1 2011 12 15 4 2113 2217 AA
#> 2 2011 12 16 5 2004 2128 AA
#> 3 2011 12 18 7 2007 2113 AA
#> 4 2011 12 19 1 2108 2223 AA
#> 5 2011 12 20 2 2008 2107 AA
#> 6 2011 12 21 3 2025 2124 AA
#> 7 2011 12 22 4 2021 2118 AA
#> 8 2011 12 23 5 2015 2118 AA
#> 9 2011 12 26 1 2013 2118 AA
#> 10 2011 12 27 2 2007 2123 AA
#> # ... with 227,486 more rows, and 14 more variables: FlightNum <int>,
#> # TailNum <chr>, ActualElapsedTime <int>, AirTime <int>, ArrDelay <int>,
#> # DepDelay <int>, Origin <chr>, Dest <chr>, Distance <int>,
#> # TaxiIn <int>, TaxiOut <int>, Cancelled <int>, CancellationCode <chr>,
#> # Diverted <int>함수 select(), mutate()를 이용한 열의 조작
함수 select()는 열(column)을 추출합니다. 복수의 열을 추출할 때에는 콤마(,)로 구분하며 인접한 열을 추출할 때에는 : 연산자를 이용할 수 있습니다.
지정한 열 이외의 다른 열을 추출하고 싶을 때는 괄호 안에 제외하고 하고 싶은 열의 이름을 지정하고 괄호 앞에 - 부호를 붙여줍니다.
> # Year, Month, DayOfWeek 열을 추출
> select(hflights_df, Year, Month, DayOfWeek)#> # A tibble: 227,496 x 3
#> Year Month DayOfWeek
#> * <int> <int> <int>
#> 1 2011 1 6
#> 2 2011 1 7
#> 3 2011 1 1
#> 4 2011 1 2
#> 5 2011 1 3
#> 6 2011 1 4
#> 7 2011 1 5
#> 8 2011 1 6
#> 9 2011 1 7
#> 10 2011 1 1
#> # ... with 227,486 more rows> # Year부터 DayOfWeek까지 추출(Year, Month, DayofMonth, DayofWeek)
> select(hflights_df, Year:DayOfWeek)#> # A tibble: 227,496 x 4
#> Year Month DayofMonth DayOfWeek
#> * <int> <int> <int> <int>
#> 1 2011 1 1 6
#> 2 2011 1 2 7
#> 3 2011 1 3 1
#> 4 2011 1 4 2
#> 5 2011 1 5 3
#> 6 2011 1 6 4
#> 7 2011 1 7 5
#> 8 2011 1 8 6
#> 9 2011 1 9 7
#> 10 2011 1 10 1
#> # ... with 227,486 more rows> # Year부터 DayOfWeek를 제외한 나머지 열을 추출
> select(hflights_df, -(Year:DayOfWeek))#> # A tibble: 227,496 x 17
#> DepTime ArrTime UniqueCarrier FlightNum TailNum ActualElapsedTime
#> * <int> <int> <chr> <int> <chr> <int>
#> 1 1400 1500 AA 428 N576AA 60
#> 2 1401 1501 AA 428 N557AA 60
#> 3 1352 1502 AA 428 N541AA 70
#> 4 1403 1513 AA 428 N403AA 70
#> 5 1405 1507 AA 428 N492AA 62
#> 6 1359 1503 AA 428 N262AA 64
#> 7 1359 1509 AA 428 N493AA 70
#> 8 1355 1454 AA 428 N477AA 59
#> 9 1443 1554 AA 428 N476AA 71
#> 10 1443 1553 AA 428 N504AA 70
#> # ... with 227,486 more rows, and 11 more variables: AirTime <int>,
#> # ArrDelay <int>, DepDelay <int>, Origin <chr>, Dest <chr>,
#> # Distance <int>, TaxiIn <int>, TaxiOut <int>, Cancelled <int>,
#> # CancellationCode <chr>, Diverted <int>함수 mutate()는 열을 추가할 때 사용합니다.
비슷한 기능을 하는 함수로 transform()이 있지만, 함수 mutate()는 함수에서 새로 만든 열을 같은 함수 안에서 바로 사용할 수 있는 장점이 있습니다. 글보다는 예제를 보는 것이 이해가 빠를 것 같습니다.
> # 생성된 열 gain을 gain_per_hour의 계산에 사용할 수 있음
> mutate(hflights_df, gain = ArrDelay - DepDelay, gain_per_hour = gain/(AirTime/60))#> # A tibble: 227,496 x 23
#> Year Month DayofMonth DayOfWeek DepTime ArrTime UniqueCarrier
#> <int> <int> <int> <int> <int> <int> <chr>
#> 1 2011 1 1 6 1400 1500 AA
#> 2 2011 1 2 7 1401 1501 AA
#> 3 2011 1 3 1 1352 1502 AA
#> 4 2011 1 4 2 1403 1513 AA
#> 5 2011 1 5 3 1405 1507 AA
#> 6 2011 1 6 4 1359 1503 AA
#> 7 2011 1 7 5 1359 1509 AA
#> 8 2011 1 8 6 1355 1454 AA
#> 9 2011 1 9 7 1443 1554 AA
#> 10 2011 1 10 1 1443 1553 AA
#> # ... with 227,486 more rows, and 16 more variables: FlightNum <int>,
#> # TailNum <chr>, ActualElapsedTime <int>, AirTime <int>, ArrDelay <int>,
#> # DepDelay <int>, Origin <chr>, Dest <chr>, Distance <int>,
#> # TaxiIn <int>, TaxiOut <int>, Cancelled <int>, CancellationCode <chr>,
#> # Diverted <int>, gain <int>, gain_per_hour <dbl>> # 생성된 열 gain을 gain_per_hour의 계산에 사용할 수 없음
> transform(hflights, gain = ArrDelay - DepDelay, gain_per_hour = gain/(AirTime/60))#> Error in eval(substitute(list(...)), `_data`, parent.frame()): object 'gain' not found함수 summarise()를 이용한 집계
함수 summarise()는 mean(), sd(), var(), median() 등의 함수를 지정하여 기초 통계량을 구할 수 있습니다. 결과값이 데이터 프레임 형식으로 돌아오는 것에 주의하세요.
> # 평균 출발지연시간 계산
> summarise(hflights_df, delay = mean(DepDelay, na.rm = TRUE))#> # A tibble: 1 x 1
#> delay
#> <dbl>
#> 1 9.44함수 group_by()를 이용한 그룹화
함수 group_by()에서 지정한 열의 수준(level)별로 그룹화된 결과를 얻을 수 있습니다.
예를 들어 비행편수 20편 이상, 평균 비행 거리 2,000마일 이상인 항공사별 평균 연착시간을 계산하여 그림으로 표현하는 코드는 다음과 같습니다.
> planes <- group_by(hflights_df, TailNum)
> delay <- summarise(planes, count = n(),
+ dist = mean(Distance, na.rm = TRUE),
+ delay = mean(ArrDelay, na.rm = TRUE))
> delay <- filter(delay, count > 20, dist < 2000)
>
> library(ggplot2)
> ggplot(delay, aes(dist, delay)) +
+ geom_point(aes(size = count), alpha = 1/2) +
+ geom_smooth() +
+ scale_size_area()#> `geom_smooth()` using method = 'gam' and formula 'y ~ s(x, bs = "cs")'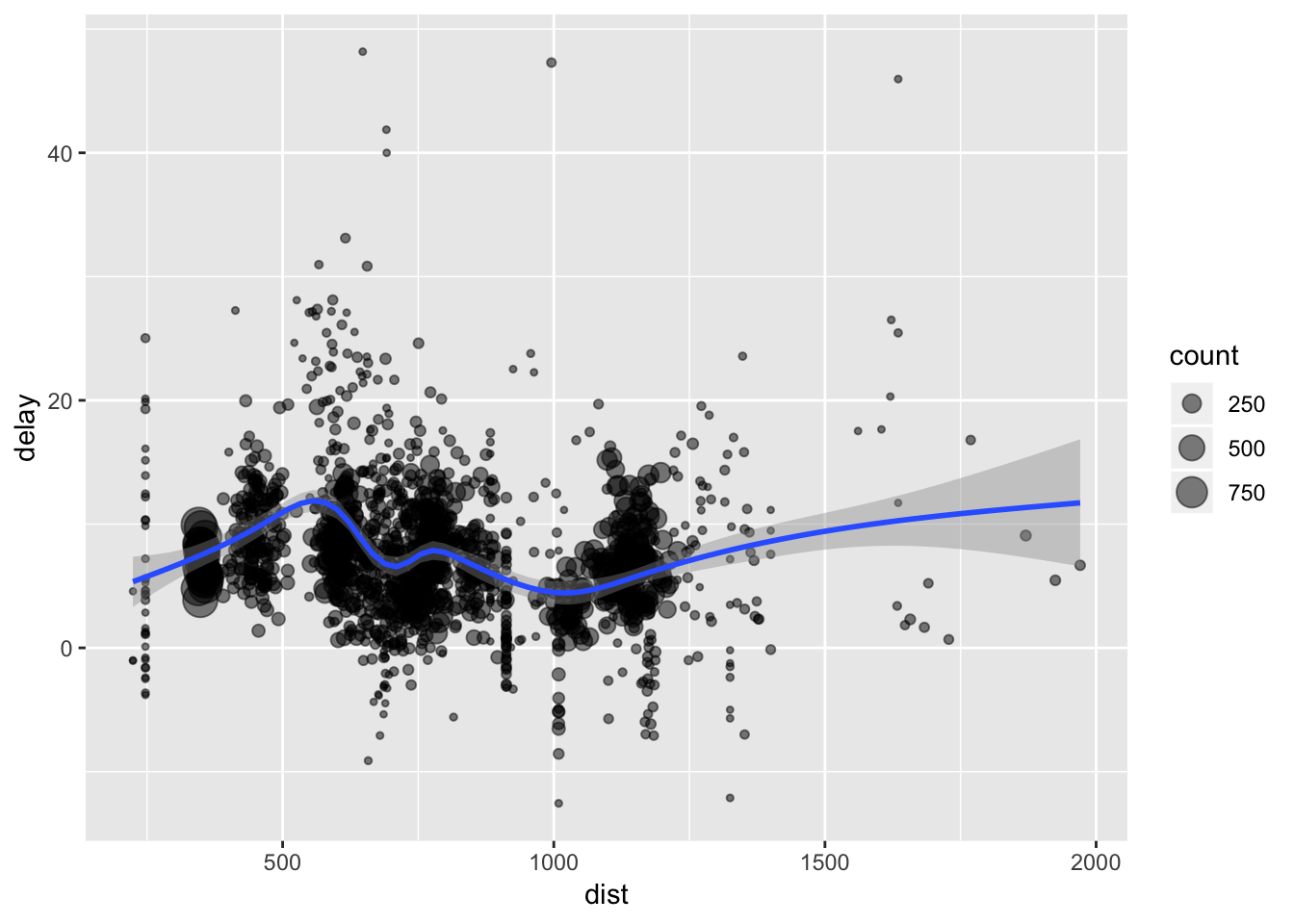
함수 group_by()의 더 많은 예제는 이 글의 참고에서 언급한 패키지 안에 포함된 소개문서를 참고하세요.
dplyr 패키지의 백미, chain() 함수
함수 chain() 혹은 간단히 %>%를 이용함으로써 각 조작을 연결해서 한 번에 수행할 수 있습니다. 즉, 최종 결과를 얻기 위해 임시로 데이터 프레임을 만들지 않아도 되는 편리한 기능입니다. 개인적으로는 dplyr 패키지의 백미라고 생각합니다.
지금까지 일관되게 첫 번째 인수에 데이터 프레임을 지정했습니다. 그러나 %>%로 연결하면 가장 먼저 데이터 프레임을 지정하면 그다음부터는 인수를 생략할 수 있을 뿐 아니라 앞선 함수의 결과(데이터 프레임)를 뒤에 오는 함수의 입력값으로 사용하게 됩니다. 역시 예제를 실행해 확인해 보는 것이 좋겠죠.
> a1 <- group_by(hflights, Year, Month, DayofMonth)
> a2 <- select(a1, Year:DayofMonth, ArrDelay, DepDelay)
> a3 <- summarise(a2, arr = mean(ArrDelay, na.rm = TRUE),
+ dep = mean(DepDelay, na.rm = TRUE))
> a4 <- filter(a3, arr > 30 | dep > 30)위 예제는 hflights 데이터를 a1) Year, Month, DayofMonth의 수준별로 그룹화, a2) Year부터 DayofMonth, ArrDelay, DepDealy 열을 선택, a3) 평균 연착시간과 평균 출발 지연시간을 구하고, a4) 평균 연착시간과 평균 출발지연시간이 30분 이상인 데이터를 추출한 결과입니다. 위 예제를 %>% 함수를 이용하면 다음과 같습니다.
> hflights_df %>%
+ group_by(Year, Month, DayofMonth) %>%
+ summarise(arr = mean(ArrDelay, na.rm = TRUE),
+ dep = mean(DepDelay, na.rm = TRUE)) %>%
+ filter(arr > 30 | dep > 30)#> # A tibble: 14 x 5
#> # Groups: Year, Month [10]
#> Year Month DayofMonth arr dep
#> <int> <int> <int> <dbl> <dbl>
#> 1 2011 2 4 44.1 47.2
#> 2 2011 3 3 35.1 38.2
#> 3 2011 3 14 46.6 36.1
#> 4 2011 4 4 38.7 27.9
#> 5 2011 4 25 37.8 22.3
#> 6 2011 5 12 69.5 64.5
#> 7 2011 5 20 37.0 26.6
#> 8 2011 6 22 65.5 62.3
#> 9 2011 7 29 29.6 31.9
#> 10 2011 9 29 39.2 32.5
#> 11 2011 10 9 61.9 59.5
#> 12 2011 11 15 43.7 39.2
#> 13 2011 12 29 26.3 30.8
#> 14 2011 12 31 46.5 54.2맺음말
Hadley Wickham가 작성한 여러 패키지를 쓰다 보면 R이라는 통계분석에 특화된 언어(DSL; Domain specific language)의 영역에서 자신의 가치관을 반영한 패키지를 연달아서 내놓는 열정에 감탄하게 됩니다. 사용자 입장에서야 편리하고 빠른 패키지를 만들어 주어서 고마울 뿐이죠.
패키지 안에 포함된 소개문서는 패키지 인스톨 후,
> vignette("introduction", package = "dplyr")을 실행하거나 R project 사이트의 Introduction to dplyr에서 확인할 수 있습니다.